7. Virtual Screening#
Objectives#
Perform virtual screening against PubChem using ligand-based approach
Apply filters to prioritize virtual screening hit list.
Learn how to use pandas’ data frame.
In this notebook, we perform virtual screening against PubChem using a set of known ligands for muscle glycogen phosphorylase. Compound filters will be applied to identify drug-like compounds and unique structures in terms of canonical SMILES will be selected to remove redundant structures. For some top-ranked compounds in the list, their binding mode will be predicted using molecular docking (which will be covered in a separate assignment).
1. Read known ligands from a file.#
As a starting point, let’s download a set of known ligands against muscle glycogen phosphorylase. These data are obtained from the DUD-E (Directory of Useful Decoys, Enhanced) data sets (http://dude.docking.org/), which contain known actives and inactives for 102 protein targets. The DUD-E sets are widely used in benchmarking studies that compare the performance of different virtual screening approaches (https://doi.org/10.1021/jm300687e).
Go to the DUD-E target page (http://dude.docking.org/targets) and find muscle glycogen phosphorylase (Target Name: PYGM, PDB ID: 1c8k) from the target list. Clicking the target name “PYGM” directs you to the page that lists various files (http://dude.docking.org/targets/pygm). Download file “actives_final.ism”, which contains the SMILES strings of known actives. Rename the file name as “pygm_1c8k_actives.ism”. [Open the file in WordPad or other text viewer/editor to check the format of this file].
Now read the data from the file using the pandas library (https://pandas.pydata.org/). Please go through some tutorials available at https://pandas.pydata.org/pandas-docs/version/0.15/tutorials.html
import pandas as pd
colnames = ['smiles','dat', 'id']
df_act = pd.read_csv("pygm_1c8k_actives.ism", sep=" ", names=colnames)
df_act.head(5)
| smiles | dat | id | |
|---|---|---|---|
| 0 | c1ccc2cc(c(cc2c1)NC(=O)c3cc(ccn3)N(=O)=O)Oc4cc... | 220668 | CHEMBL134802 |
| 1 | CC1=C(C(C(=C(N1Cc2ccc(cc2)Cl)C(=O)O)C(=O)O)c3c... | 189331 | CHEMBL115651 |
| 2 | CCN1C(=C(C(C(=C1C(=O)O)C(=O)O)c2ccccc2Cl)C(=O)... | 188996 | CHEMBL113736 |
| 3 | c1cc(c(c(c1)F)NC(=O)c2cc(ccn2)N(=O)=O)Oc3ccc(c... | 219845 | CHEMBL133911 |
| 4 | CC1=C(C(C(=C(N1Cc2cccc(c2)N(=O)=O)C(=O)O)C(=O)... | 189034 | CHEMBL423509 |
print(len(df_act)) # Show how many structures are in the "data frame"
77
2. Similarity Search against PubChem#
Now, let’s perform similarity search against PubChem using each known active compound as a query. There are a few things to mention in this step:
The isomeric SMILES string is available for each query compound. This string will be used to specify the input structure, so HTTP POST should be used. (Please review lecture02-structure-inputs.ipynb)
During PubChem’s similarity search, molecular similarity is evaluated using the PubChem fingerprints and Tanimoto coefficient. By default, similarity search will return compounds with Tanimoter scores of 0.9 or higher. While we will use the default threshold in this practice, it is noteworthy that it is adjustable. If you use a higher threshold (e.g., 0.99), you will get a fewer hits, which are too similar to the query compounds. If you use a lower threshold (e.g., 0.88), you will get more hits, but they will include more false positives.
PubChem’s similarity search does not return the similarity scores between the query and hit compounds. Only the hit compound list is returned, which makes it difficult to rank the hit compounds for compound selection. To address this issue, for each hit compound, we compute the number of query compounds that returned that compound as a hit. [Because we are using multiple query compounds for similarity search, it is possible for different query compounds to return the same compound as a hit. That is, the hit compound may be similar to multiple query compounds. The underlying assumption is that hit compounds returned multiple times from different queries are more likely to be active than those returned only once from a single query.]
Add “time.sleep()” to avoid overloading PubChem servers and getting blocked.
smiles_act = df_act.smiles.to_list()
import time
import requests
prolog = "https://pubchem.ncbi.nlm.nih.gov/rest/pug"
cids_hit = dict()
for idx, mysmiles in enumerate(smiles_act) :
mydata = { 'smiles' : mysmiles }
url = prolog + "/compound/fastsimilarity_2d/smiles/cids/txt"
res = requests.post(url, data=mydata)
if ( res.status_code == 200 ) :
cids = res.text.split()
cids = [ int(x) for x in cids ] # Convert CIDs from string to integer.
else :
print("Error at", idx, ":", df_act.loc[idx,'id'], mysmiles )
print(res.status_code)
print(res.content)
for mycid in cids:
cids_hit[mycid] = cids_hit.get(mycid, 0) + 1
time.sleep(0.2)
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[5], line 13
10 mydata = { 'smiles' : mysmiles }
12 url = prolog + "/compound/fastsimilarity_2d/smiles/cids/txt"
---> 13 res = requests.post(url, data=mydata)
15 if ( res.status_code == 200 ) :
16 cids = res.text.split()
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/requests/api.py:115, in post(url, data, json, **kwargs)
103 def post(url, data=None, json=None, **kwargs):
104 r"""Sends a POST request.
105
106 :param url: URL for the new :class:`Request` object.
(...)
112 :rtype: requests.Response
113 """
--> 115 return request("post", url, data=data, json=json, **kwargs)
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/requests/api.py:59, in request(method, url, **kwargs)
55 # By using the 'with' statement we are sure the session is closed, thus we
56 # avoid leaving sockets open which can trigger a ResourceWarning in some
57 # cases, and look like a memory leak in others.
58 with sessions.Session() as session:
---> 59 return session.request(method=method, url=url, **kwargs)
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/requests/sessions.py:589, in Session.request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json)
584 send_kwargs = {
585 "timeout": timeout,
586 "allow_redirects": allow_redirects,
587 }
588 send_kwargs.update(settings)
--> 589 resp = self.send(prep, **send_kwargs)
591 return resp
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/requests/sessions.py:703, in Session.send(self, request, **kwargs)
700 start = preferred_clock()
702 # Send the request
--> 703 r = adapter.send(request, **kwargs)
705 # Total elapsed time of the request (approximately)
706 elapsed = preferred_clock() - start
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/requests/adapters.py:667, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
664 timeout = TimeoutSauce(connect=timeout, read=timeout)
666 try:
--> 667 resp = conn.urlopen(
668 method=request.method,
669 url=url,
670 body=request.body,
671 headers=request.headers,
672 redirect=False,
673 assert_same_host=False,
674 preload_content=False,
675 decode_content=False,
676 retries=self.max_retries,
677 timeout=timeout,
678 chunked=chunked,
679 )
681 except (ProtocolError, OSError) as err:
682 raise ConnectionError(err, request=request)
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/urllib3/connectionpool.py:787, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, preload_content, decode_content, **response_kw)
784 response_conn = conn if not release_conn else None
786 # Make the request on the HTTPConnection object
--> 787 response = self._make_request(
788 conn,
789 method,
790 url,
791 timeout=timeout_obj,
792 body=body,
793 headers=headers,
794 chunked=chunked,
795 retries=retries,
796 response_conn=response_conn,
797 preload_content=preload_content,
798 decode_content=decode_content,
799 **response_kw,
800 )
802 # Everything went great!
803 clean_exit = True
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/urllib3/connectionpool.py:534, in HTTPConnectionPool._make_request(self, conn, method, url, body, headers, retries, timeout, chunked, response_conn, preload_content, decode_content, enforce_content_length)
532 # Receive the response from the server
533 try:
--> 534 response = conn.getresponse()
535 except (BaseSSLError, OSError) as e:
536 self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File ~/Desktop/my-book-files/venv/lib64/python3.9/site-packages/urllib3/connection.py:516, in HTTPConnection.getresponse(self)
513 _shutdown = getattr(self.sock, "shutdown", None)
515 # Get the response from http.client.HTTPConnection
--> 516 httplib_response = super().getresponse()
518 try:
519 assert_header_parsing(httplib_response.msg)
File /usr/lib64/python3.9/http/client.py:1377, in HTTPConnection.getresponse(self)
1375 try:
1376 try:
-> 1377 response.begin()
1378 except ConnectionError:
1379 self.close()
File /usr/lib64/python3.9/http/client.py:320, in HTTPResponse.begin(self)
318 # read until we get a non-100 response
319 while True:
--> 320 version, status, reason = self._read_status()
321 if status != CONTINUE:
322 break
File /usr/lib64/python3.9/http/client.py:281, in HTTPResponse._read_status(self)
280 def _read_status(self):
--> 281 line = str(self.fp.readline(_MAXLINE + 1), "iso-8859-1")
282 if len(line) > _MAXLINE:
283 raise LineTooLong("status line")
File /usr/lib64/python3.9/socket.py:716, in SocketIO.readinto(self, b)
714 while True:
715 try:
--> 716 return self._sock.recv_into(b)
717 except timeout:
718 self._timeout_occurred = True
File /usr/lib64/python3.9/ssl.py:1275, in SSLSocket.recv_into(self, buffer, nbytes, flags)
1271 if flags != 0:
1272 raise ValueError(
1273 "non-zero flags not allowed in calls to recv_into() on %s" %
1274 self.__class__)
-> 1275 return self.read(nbytes, buffer)
1276 else:
1277 return super().recv_into(buffer, nbytes, flags)
File /usr/lib64/python3.9/ssl.py:1133, in SSLSocket.read(self, len, buffer)
1131 try:
1132 if buffer is not None:
-> 1133 return self._sslobj.read(len, buffer)
1134 else:
1135 return self._sslobj.read(len)
KeyboardInterrupt:
len(cids_hit) # Show the number of compounds returned from any query.
23981
In the above code cells, the returned hits are stored in a dictionary, along with the number of times they are returned. Let’s print the top 10 compounds that are returned the most number of times from the search.
sorted_by_freq = [ (v, k) for k, v in cids_hit.items() ]
sorted_by_freq.sort(reverse=True)
for v, k in enumerate(sorted_by_freq) :
if v == 10 :
break
print(v, k) # Print (frequency, CID)
0 (16, 44354348)
1 (15, 44354370)
2 (15, 44354349)
3 (15, 44354322)
4 (13, 44357907)
5 (12, 44357938)
6 (12, 44357937)
7 (12, 44354455)
8 (12, 44354454)
9 (12, 44354362)
3. Exclude the query compounds from the hits#
In the previous step, we repeated similarity searches using multiple query molecules. This may result in a query molecule being returned as a hit from similarity search using another query molecule. Therefore, we want to check if the hit compound list has any query compounds and if any, we want to remove them. Below, we search PubChem for compounds identical to the query molecules and remove them from the hit compound list.
Note that the identity_type parameter in the PUG-REST request is set to “same_connectivity”, which will return compounds with the same connectivity with the query molecule (ignoring stereochemistry and isotope information). The default for this parameter is “same_stereo_isotope”, which returns compounds with the same stereochemistry AND isotope information.
cids_query = dict()
for idx, mysmiles in enumerate(smiles_act) :
mydata = { 'smiles' : mysmiles }
url = prolog + "/compound/fastidentity/smiles/cids/txt?identity_type=same_connectivity"
res = requests.post(url, data=mydata)
if ( res.status_code == 200 ) :
cids = res.text.split()
cids = [ int(x) for x in cids]
else :
print("Error at", idx, ":", df_act.loc[idx,'id'], mysmiles )
print(res.status_code)
print(res.content)
for mycid in cids:
cids_query[mycid] = cids_query.get(mycid, 0) + 1
time.sleep(0.2)
len(cids_query.keys()) # Show the number of CIDs that represent the query compounds.
133
Now remove the query compounds from the hit list (if they are found in the list)
for mycid in cids_query.keys() :
cids_hit.pop(mycid, None)
len(cids_hit)
23848
Print the top 10 compounds in the current hit list and compare them with the old ones.
sorted_by_freq = [ (v, k) for k, v in cids_hit.items() ]
sorted_by_freq.sort(reverse=True)
for v, k in enumerate(sorted_by_freq) :
if v == 10 :
break
print(v, k) # Print (frequency, CID)
0 (12, 11779854)
1 (11, 118078858)
2 (11, 93077065)
3 (11, 93077064)
4 (11, 53013349)
5 (11, 51808718)
6 (11, 45369696)
7 (11, 17600716)
8 (10, 131851009)
9 (10, 129567524)
4. Filtering out non-drug-like compounds#
In this step, non-drug-like compounds are filtered out from the list. To do that, four molecular properties are downloaded from PubChem and stored in CSV.
chunk_size = 100
if ( len(cids_hit) % chunk_size == 0 ) :
num_chunks = len(cids_hit) // chunk_size
else :
num_chunks = len(cids_hit) // chunk_size + 1
cids_list = list(cids_hit.keys())
print("# Number of chunks:", num_chunks )
csv = "" #sets a variable called csv to save the comma separated output
for i in range(num_chunks) :
print(i, end=" ")
idx1 = chunk_size * i
idx2 = chunk_size * (i + 1)
cids_str = ",".join([ str(x) for x in cids_list[idx1:idx2] ]) # build pug input for chunks of data
url = prolog + "/compound/cid/" + cids_str + "/property/HBondDonorCount,HBondAcceptorCount,MolecularWeight,XLogP,CanonicalSMILES,IsomericSMILES/csv"
res = requests.get(url)
if ( i == 0 ) : # if this is the first request, store result in empty csv variable
csv = res.text
else : # if this is a subsequent request, add the request to the csv variable adding a new line between chunks
csv = csv + "\n".join(res.text.split()[1:]) + "\n"
time.sleep(0.2)
#print(csv)
# Number of chunks: 239
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238
Downloaded data (in CSV) are loaded into a pandas data frame.
from io import StringIO
csv_file = StringIO(csv)
df_raw = pd.read_csv(csv_file, sep=",")
df_raw.shape # Show the shape (dimesnion) of the data frame
(23848, 7)
df_raw.head(5) # Show the first 5 rows of the data frame
| CID | HBondDonorCount | HBondAcceptorCount | MolecularWeight | XLogP | CanonicalSMILES | IsomericSMILES | |
|---|---|---|---|---|---|---|---|
| 0 | 1731763 | 0 | 5 | 454.0 | 5.5 | CCOC(=O)C1=C(N(C(=C(C1C2=CC=C(C=C2)Cl)C(=O)OCC... | CCOC(=O)C1=C(N(C(=C(C1C2=CC=C(C=C2)Cl)C(=O)OCC... |
| 1 | 21795259 | 0 | 5 | 454.0 | 5.5 | CCOC(=O)C1=C(N(C(=C(C1C2=CC=CC=C2Cl)C(=O)OCC)C... | CCOC(=O)C1=C(N(C(=C(C1C2=CC=CC=C2Cl)C(=O)OCC)C... |
| 2 | 9910160 | 3 | 4 | 422.9 | 4.4 | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... |
| 3 | 70157737 | 2 | 4 | 436.9 | 4.6 | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... |
| 4 | 70074958 | 2 | 6 | 448.9 | 3.9 | CC1=C(C(C(=C(N1)C)C(=O)OC)C2=CC=CC=C2Cl)C(=O)N... | CC1=C([C@@H](C(=C(N1)C)C(=O)OC)C2=CC=CC=C2Cl)C... |
Note that some compounds do not have computed XLogP values (because XLogP algorithm cannot handle inorganic compounds, salts, and mixtures) and we want to remove them.
df_raw.isna().sum() # Check if there are any NULL values.
CID 0
HBondDonorCount 0
HBondAcceptorCount 0
MolecularWeight 0
XLogP 477
CanonicalSMILES 0
IsomericSMILES 0
dtype: int64
len(df_raw) # Check the number of rows (which is equals to the number of CIDs)
23848
For convenience, add the information contained in the cids_hit dictionary to this data frame
# First load the cids_hit dictionary into a data frame.
df_freq = pd.DataFrame( cids_hit.items(), columns=['CID','HitFreq'])
df_freq.head(5)
| CID | HitFreq | |
|---|---|---|
| 0 | 1731763 | 2 |
| 1 | 21795259 | 4 |
| 2 | 9910160 | 3 |
| 3 | 70157737 | 3 |
| 4 | 70074958 | 3 |
# Double-check if the data are loaded correctly
# Compare the data with those from Cell [12]
df_freq.sort_values(by=['HitFreq', 'CID'], ascending=False).head(10)
| CID | HitFreq | |
|---|---|---|
| 1022 | 11779854 | 12 |
| 372 | 118078858 | 11 |
| 2631 | 93077065 | 11 |
| 2630 | 93077064 | 11 |
| 1983 | 53013349 | 11 |
| 1941 | 51808718 | 11 |
| 1707 | 45369696 | 11 |
| 1467 | 17600716 | 11 |
| 3072 | 131851009 | 10 |
| 3067 | 129567524 | 10 |
# Create a new data frame called "df" by joining the df and df_freq data frames
df = df_raw.join(df_freq.set_index('CID'), on='CID')
df.shape
(23848, 8)
df.sort_values(by=['HitFreq', 'CID'], ascending=False).head(10)
| CID | HBondDonorCount | HBondAcceptorCount | MolecularWeight | XLogP | CanonicalSMILES | IsomericSMILES | HitFreq | |
|---|---|---|---|---|---|---|---|---|
| 1022 | 11779854 | 3 | 2 | 305.3 | 2.6 | C1C(C(=O)NC2=CC=CC=C21)NC(=O)C3=CC4=CC=CC=C4N3 | C1C(C(=O)NC2=CC=CC=C21)NC(=O)C3=CC4=CC=CC=C4N3 | 12 |
| 372 | 118078858 | 1 | 2 | 333.4 | 3.0 | CC1CN(C2=CC=CC=C2N1C(=O)C)C(=O)C3=CC4=CC=CC=C4N3 | C[C@H]1CN(C2=CC=CC=C2N1C(=O)C)C(=O)C3=CC4=CC=C... | 11 |
| 2631 | 93077065 | 2 | 2 | 409.5 | 4.8 | C1CC2=CC=CC=C2N(C1)C(=O)C(C3=CC=CC=C3)NC(=O)C4... | C1CC2=CC=CC=C2N(C1)C(=O)[C@@H](C3=CC=CC=C3)NC(... | 11 |
| 2630 | 93077064 | 2 | 2 | 409.5 | 4.8 | C1CC2=CC=CC=C2N(C1)C(=O)C(C3=CC=CC=C3)NC(=O)C4... | C1CC2=CC=CC=C2N(C1)C(=O)[C@H](C3=CC=CC=C3)NC(=... | 11 |
| 1983 | 53013349 | 2 | 2 | 409.5 | 4.8 | C1CC2=CC=CC=C2N(C1)C(=O)C(C3=CC=CC=C3)NC(=O)C4... | C1CC2=CC=CC=C2N(C1)C(=O)C(C3=CC=CC=C3)NC(=O)C4... | 11 |
| 1941 | 51808718 | 2 | 3 | 390.5 | 2.9 | CC(C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=CC4=CC... | C[C@H](C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=CC... | 11 |
| 1707 | 45369696 | 2 | 3 | 390.5 | 2.9 | CC(C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=CC4=CC... | CC(C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=CC4=CC... | 11 |
| 1467 | 17600716 | 2 | 3 | 390.5 | 2.9 | CC(C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=CC4=CC... | C[C@@H](C(=O)N1CCN(CC1)CC2=CC=CC=C2)NC(=O)C3=C... | 11 |
| 3072 | 131851009 | 1 | 2 | 347.4 | 3.1 | CN1CCN(C(C1=O)CC2=CC=CC=C2)C(=O)C3=CC4=CC=CC=C4N3 | CN1CCN([C@H](C1=O)CC2=CC=CC=C2)C(=O)C3=CC4=CC=... | 10 |
| 3067 | 129567524 | 1 | 2 | 347.4 | 2.6 | CC(=O)N1CCN(CC1C2=CC=CC=C2)C(=O)C3=CC4=CC=CC=C4N3 | CC(=O)N1CCN(C[C@@H]1C2=CC=CC=C2)C(=O)C3=CC4=CC... | 10 |
Now identify and remove those compounds that satisfy all criteria of Lipinski’s rule of five.
len(df[ df['HBondDonorCount'] <= 5 ])
23803
len(df[ df['HBondAcceptorCount'] <= 10 ])
23830
len(df[ df['MolecularWeight'] <= 500 ])
23238
len(df[ df['XLogP'] < 5 ])
21105
df = df[ ( df['HBondDonorCount'] <= 5) &
( df['HBondAcceptorCount'] <= 10 ) &
( df['MolecularWeight'] <= 500 ) &
( df['XLogP'] < 5 ) ]
len(df)
20827
5. Draw the structures of the top 10 compounds#
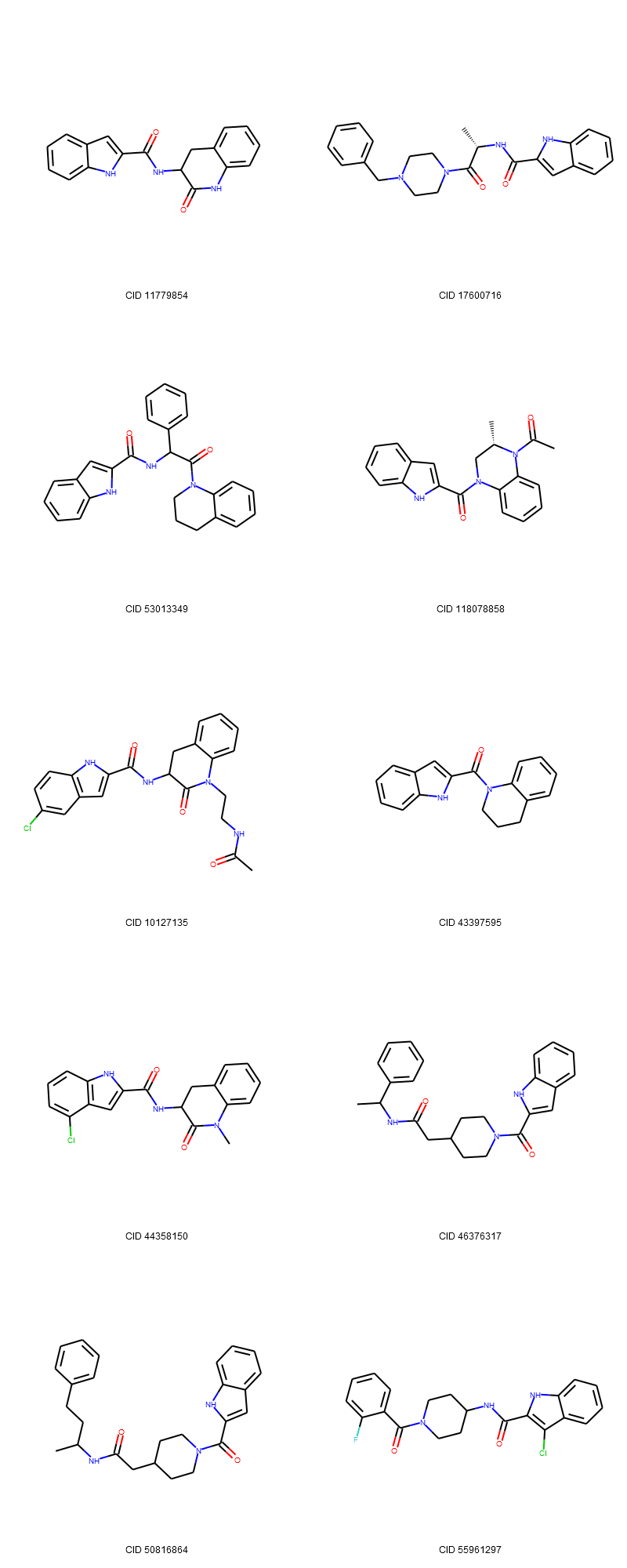
Let’s check the structure of the top 10 compounds in the hit list.
cids_top = df.sort_values(by=['HitFreq', 'CID'], ascending=False).head(10).CID.to_list()
from rdkit import Chem
from rdkit.Chem import Draw
mols = []
for mycid in cids_top :
mysmiles = df[ df.CID==mycid ].IsomericSMILES.item()
mol = Chem.MolFromSmiles( mysmiles )
Chem.FindPotentialStereoBonds(mol) # Identify potential stereo bonds!
mols.append(mol)
mylegends = [ "CID " + str(x) for x in cids_top ]
img = Draw.MolsToGridImage(mols, molsPerRow=2, subImgSize=(400,400), legends=mylegends)
display(img)
RDKit WARNING: [10:47:56] Enabling RDKit 2019.09.1 jupyter extensions
C:\Users\rebelford\AppData\Local\Continuum\anaconda3\envs\olcc2019\lib\site-packages\ipykernel_launcher.py:8: FutureWarning: `item` has been deprecated and will be removed in a future version
An important observation from these images is that the hit list contains multiple compounds with the same connectivity. For example, CIDs 93077065 and 93077064 are stereoisomers of each other and CID 53013349 has the same connectivity as the two CIDs, but with its stereocenter being unspecified. When performing a screening with limited resources in the early stage of drug discovery, you may want to test as diverse molecules as possible, avoiding testing too similar structures.
To do so, let’s look into PubChem’s canonical SMILES strings, which do not encode the stereochemisry and isotope information. Chemicals with the same connectivity but with different stereochemistry/isotopes should have the same canonical SMILES. In the next section, we select unique compounds in terms of canonical SMILES to reduce the number of compounds to screen.
6. Extract unique compounds in terms of canonical SMILES#
The next few cells show how to get unique values within a column (in this case, unique canonical SMILES).
len(df)
20827
len(df.CanonicalSMILES.unique())
16543
canonical_smiles = df.CanonicalSMILES.unique()
df[ df.CanonicalSMILES == canonical_smiles[0] ]
| CID | HBondDonorCount | HBondAcceptorCount | MolecularWeight | XLogP | CanonicalSMILES | IsomericSMILES | HitFreq | |
|---|---|---|---|---|---|---|---|---|
| 2 | 9910160 | 3 | 4 | 422.9 | 4.4 | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | 3 |
df[ df.CanonicalSMILES == canonical_smiles[1] ]
| CID | HBondDonorCount | HBondAcceptorCount | MolecularWeight | XLogP | CanonicalSMILES | IsomericSMILES | HitFreq | |
|---|---|---|---|---|---|---|---|---|
| 3 | 70157737 | 2 | 4 | 436.9 | 4.6 | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | 3 |
| 6 | 18318317 | 2 | 4 | 436.9 | 4.6 | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)... | 3 |
df[ df.CanonicalSMILES == canonical_smiles[1] ].IsomericSMILES.to_list()
['CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)N(C)CC=CC3=CC=CC=C3',
'CC1=C(C(C(=C(N1)C)C(=O)O)C2=CC(=CC=C2)Cl)C(=O)N(C)C/C=C/C3=CC=CC=C3']
Now let’s generate a list of unique compounds in terms of canonical SMILES. If multiple compounds have the same canonical SMILES, the one that appears very first will be included in the unique compound list.
idx_to_include = []
for mysmiles in canonical_smiles :
myidx = df[ df.CanonicalSMILES == mysmiles ].index.to_list()[0]
idx_to_include.append( myidx )
len(idx_to_include)
16543
# Create a new column 'Include'
# All values initialized to 0 (not include)
df['Include'] = 0
df['Include'].sum()
0
# Now the "Include" column's value is modified if the record is in the idx_to_include list.
df.loc[idx_to_include,'Include'] = 1
df['Include'].sum()
16543
df[['CID','Include']].head(10)
| CID | Include | |
|---|---|---|
| 2 | 9910160 | 1 |
| 3 | 70157737 | 1 |
| 4 | 70074958 | 1 |
| 5 | 70073800 | 0 |
| 6 | 18318317 | 0 |
| 7 | 18318313 | 1 |
| 9 | 18318274 | 1 |
| 10 | 18318270 | 1 |
| 11 | 15838576 | 0 |
| 12 | 15838575 | 1 |
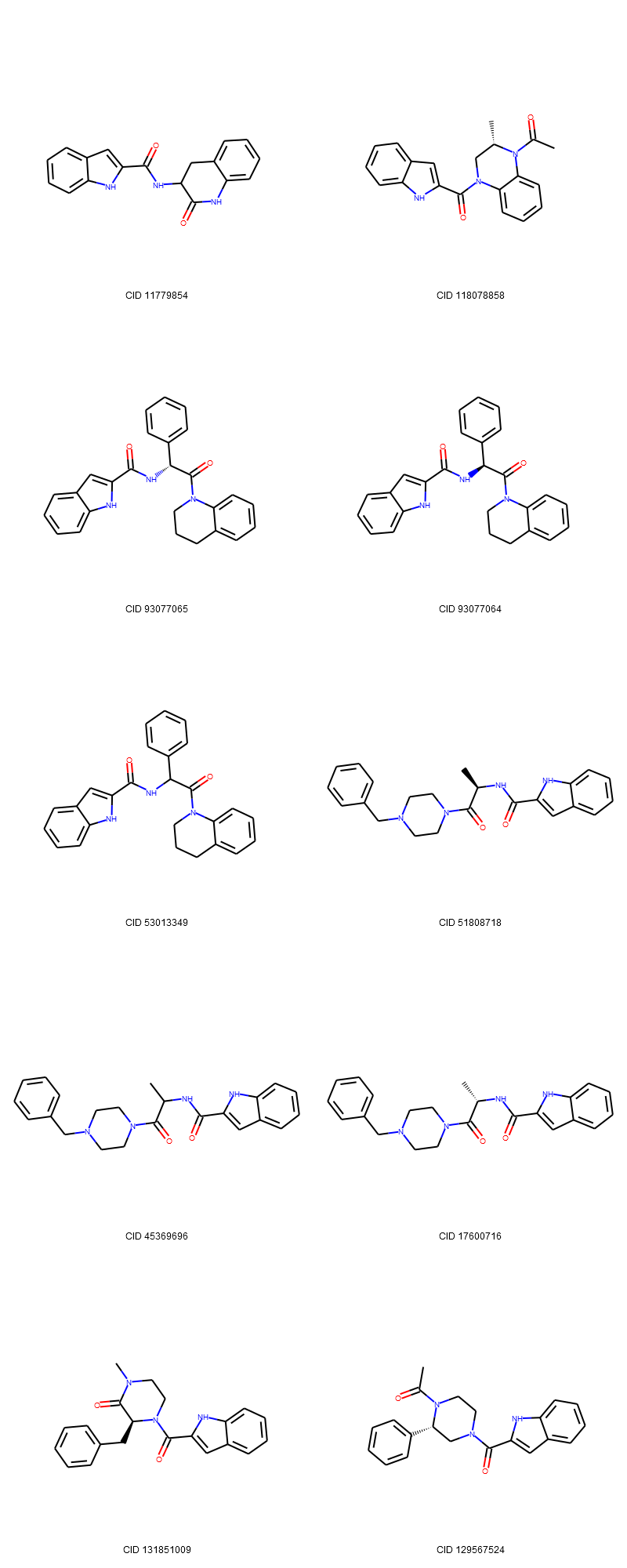
Now draw the top 10 unique compounds (in terms of canonical SMILES). Note the, the structure figures are drawn using isomeric SMILES, but canonical SMILES strings could be used.
cids_top = df[ df['Include'] == 1].sort_values(by=['HitFreq', 'CID'], ascending=False).head(10).CID.to_list()
mols = []
for mycid in cids_top :
mysmiles = df[ df.CID==mycid ].IsomericSMILES.item()
mol = Chem.MolFromSmiles( mysmiles )
Chem.FindPotentialStereoBonds(mol) # Identify potential stereo bonds!
mols.append(mol)
mylegends = [ "CID " + str(x) for x in cids_top ]
img = Draw.MolsToGridImage(mols, molsPerRow=2, subImgSize=(400,400), legends=mylegends)
display(img)
C:\Users\rebelford\AppData\Local\Continuum\anaconda3\envs\olcc2019\lib\site-packages\ipykernel_launcher.py:5: FutureWarning: `item` has been deprecated and will be removed in a future version
"""
7. Saving molecules in files#
Now save the molecules in the cids_top list in files, which will be used in molecular docking experiments. For simplicity, we will use only the top 3 compounds in the list.
from rdkit.Chem import AllChem
for idx, mycid in enumerate( cids_top ) :
if idx == 3 :
break
mysmiles = df[ df['CID'] == mycid ].IsomericSMILES.item()
mymol = Chem.MolFromSmiles(mysmiles)
mymol = Chem.AddHs(mymol)
AllChem.EmbedMolecule(mymol)
AllChem.MMFFOptimizeMolecule(mymol)
filename = "pygm_lig" + str(idx) + "_" + str(mycid) + ".mol"
Chem.MolToMolFile(mymol, filename)
C:\Users\rebelford\AppData\Local\Continuum\anaconda3\envs\olcc2019\lib\site-packages\ipykernel_launcher.py:8: FutureWarning: `item` has been deprecated and will be removed in a future version
To save all data in the df data frame (in CSV)
df.to_csv('pygm_df.csv')
Exersises#
1. From the DUD-E target list (http://dude.docking.org/targets), find cyclooxigenase-2 (Target Name: PGH2, PDB ID: 3ln1). Download the “actives_final.ism” file and save it as “pgh2_3ln1_actives.ism”. Load the data into a data frame called df_act. After loading the data, show the following information:
the number of rows of the data frame.
the first five rows of the data frame.
# Write your code in this cell
df_act.head(5)
| smiles | dat | id | |
|---|---|---|---|
| 0 | c1ccc2cc(c(cc2c1)NC(=O)c3cc(ccn3)N(=O)=O)Oc4cc... | 220668 | CHEMBL134802 |
| 1 | CC1=C(C(C(=C(N1Cc2ccc(cc2)Cl)C(=O)O)C(=O)O)c3c... | 189331 | CHEMBL115651 |
| 2 | CCN1C(=C(C(C(=C1C(=O)O)C(=O)O)c2ccccc2Cl)C(=O)... | 188996 | CHEMBL113736 |
| 3 | c1cc(c(c(c1)F)NC(=O)c2cc(ccn2)N(=O)=O)Oc3ccc(c... | 219845 | CHEMBL133911 |
| 4 | CC1=C(C(C(=C(N1Cc2cccc(c2)N(=O)=O)C(=O)O)C(=O)... | 189034 | CHEMBL423509 |
2. Perform similarity search using each of the isomeric SMILES contained in the loaded data frame.
As we did for PYGM ligands in this notebook, track the number of times a particular hit is returned from multiple queries, using a dictionary named cids_hit (CIDs as keys and the frequencies as values). This information will be used to rank the hit compounds.
Make sure that the CIDs are recognized as integers when they are used as keys in the dictionary.
Print the total number of hits returned from this step (which is the same as the number of CIDs in cids_hit.
Add time.sleep() to avoid overloading PubChem servers.
prolog = "https://pubchem.ncbi.nlm.nih.gov/rest/pug"
cids_hit = dict()
for idx, mysmiles in enumerate(df_act.smiles.to_list()) :
mydata = { 'smiles' : mysmiles }
url = prolog + "/compound/fastsimilarity_2d/smiles/cids/txt"
res = requests.post(url, data=mydata)
if ( res.status_code == 200 ) :
cids = res.text.split()
cids = [ int(x) for x in cids ]
else :
print("Error at", idx, ":", df_act.loc[idx,'id'], mysmiles )
print(res.status_code)
print(res.content)
for mycid in cids:
cids_hit[mycid] = cids_hit.get(mycid, 0) + 1
time.sleep(0.2)
len(cids_hit)
23981
3. The hit list from the above step may contain the query compounds themselves. Get the CIDs of the query compounds through idenitity search and remove them from the hit list.
Set the optional parameter “identity_type” to “same_connectivity”.
Add time.sleep() to avoid overloading PubChem servers.
Print the number of CIDs corresponding to the query compounds.
Print the number of the remaining hit compounds, after removing the query compounds from the hit list.
# Write your code in this cell
for mycid in cids_query.keys() :
cids_hit.pop(mycid, None)
len(cids_query)
133
len(cids_hit)
23848
4. Download the hydrogen donor and acceptor counts, molecular weights, XlogP, and canonical and isomeric SMILES for each compound in cids_hit. Load the downloaded data into a new data frame called df_raw. Print the size (or dimension) of the data frame using .shape.
# Write your code in this cell
from io import StringIO
csv_file = StringIO(csv)
df_raw = pd.read_csv(csv_file, sep=",")
df_raw.shape
(23848, 7)
5. Create a new data frame called df, which combines the data stored in cids_hit and df_raw.
First load the frequency data into a new data frame called df_freq and then join df_raw and df_freq into df
Print the shape (dimension) of df
# Write your code in this cell
6. Remove from df the compounds that violate any criterion of Congreve’s rule of 3 and show the number of remaining compounds (the number of rows of df).
# Write your code in this cell
7. Get the unique canonical SMILES strings from the df. Add to the df a column named ‘Include’, which contains a flag set to 1 for the lowest CID associated with each unique CID and set to 0 for other CIDs. Show the number of compounds for which this flag is set to 1.
# Write your code in this cell
idx_to_include = []
for mysmiles in canonical_smiles :
myidx = df[ df.CanonicalSMILES == mysmiles ].index.to_list()[0]
idx_to_include.append( myidx )
df['Include'] = 0
df.loc[idx_to_include,'Include'] = 1
df['Include'].sum()
16543
8. Among those with the “Include” flag set to 1, identify the top 10 compounds that were returned from the largest number of query compounds.
Sort the data frame by the number of times returned (in descending order) and then by CID (in ascending order)
For each of the 10 compounds, print its CID, isomeric SMILES, and the number of times it was returned.
For each of the 10 compounds, draw its structure (using isomeric SMILES).
# Write your code in this cell
cids_top = df[ df['Include'] == 1].sort_values(by=['HitFreq', 'CID'], ascending=[False,True]).head(10).CID.to_list()
mols = []
for mycid in cids_top :
mysmiles = df[ df.CID==mycid ].IsomericSMILES.item()
mol = Chem.MolFromSmiles( mysmiles )
Chem.FindPotentialStereoBonds(mol) # Identify potential stereo bonds!
mols.append(mol)
mylegends = [ "CID " + str(x) for x in cids_top ]
img = Draw.MolsToGridImage(mols, molsPerRow=2, subImgSize=(400,400), legends=mylegends)
display(img)
C:\Users\rebelford\AppData\Local\Continuum\anaconda3\envs\olcc2019\lib\site-packages\ipykernel_launcher.py:7: FutureWarning: `item` has been deprecated and will be removed in a future version
import sys